企业级容器服务 数据处理与存储服务的架构与实践案例
随着云计算技术的快速发展,容器技术已成为企业数字化转型的重要支撑。企业级容器服务不仅提供了高效的应用部署和管理能力,更在数据处理与存储方面展现出强大的优势。本文将深入探讨企业级容器服务的架构设计,并结合实际案例,分析其在数据处理和存储服务中的应用。
一、企业级容器服务的架构设计
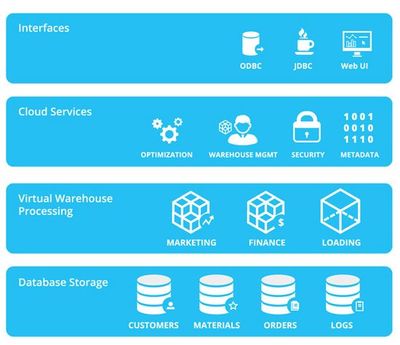
企业级容器服务的核心架构通常包括容器编排引擎、存储管理、网络管理和监控系统等关键组件。以Kubernetes为例,作为主流的容器编排平台,它通过声明式API和控制器模式,实现了应用的高可用和弹性伸缩。在数据处理与存储方面,架构设计需重点关注以下几点:
- 存储抽象层:企业级容器服务通过持久卷(Persistent Volume, PV)和持久卷声明(Persistent Volume Claim, PVC)机制,将底层存储资源抽象化,支持多种存储后端,如本地存储、网络附加存储(NAS)和云存储服务。这种设计使得应用可以无缝访问数据,同时确保数据的高可用和持久性。
- 数据流水线集成:容器服务常与数据处理框架(如Apache Spark、Flink)集成,通过容器化部署数据处理任务,实现资源的动态分配和隔离。例如,使用Kubernetes Operators可以自动化管理数据流水线,提升数据处理效率。
- 安全与合规:企业级场景下,数据安全和合规性至关重要。架构中需融入加密存储、访问控制和审计日志等功能,确保数据处理和存储符合行业标准,如GDPR或HIPAA。
二、数据处理与存储服务的案例分析
以下通过两个实际案例,展示企业级容器服务在数据处理和存储方面的应用。
案例一:金融行业实时风险分析
某大型银行采用基于Kubernetes的容器服务平台,构建实时风险分析系统。该系统处理海量交易数据,要求低延迟和高可靠性。架构中,使用持久卷连接高性能分布式存储(如Ceph),确保数据持久化;通过容器化部署Apache Kafka和Flink,实现流式数据的实时处理。结果,系统处理速度提升50%,且通过自动扩缩容应对流量峰值,显著降低了运维成本。
案例二:电商平台大数据存储与查询
一家电商企业利用容器服务优化其大数据存储和查询流程。他们部署了容器化的Apache Hive和Presto on Kubernetes,结合云原生存储解决方案(如AWS EBS或Google Persistent Disk),实现了弹性数据仓库。通过PVC动态分配存储资源,企业能够根据查询负载自动调整存储容量,提升数据查询性能30%以上,同时降低了存储成本。
三、未来展望与挑战
尽管企业级容器服务在数据处理和存储方面取得了显著成效,但仍面临数据一致性、跨云迁移等挑战。随着Serverless容器和边缘计算的发展,容器服务将更深入地与AI和IoT融合,推动企业数据驱动的创新。
企业级容器服务通过灵活的架构和实际应用案例,证明了其在数据处理和存储领域的价值。企业应结合自身需求,选择合适的容器化解决方案,以提升数据管理效率,加速业务增长。
如若转载,请注明出处:http://www.0meiyunhe.com/product/48.html
更新时间:2026-02-23 23:06:05