前端监控的数据处理与存储服务实践 —— 前端早早聊大会总结
在前端早早聊大会中,多位专家围绕『前端如何搞监控』这一主题进行了深入探讨,其中数据处理和存储服务是构建稳定、高效前端监控体系的核心环节。本文将从数据处理流程、存储方案选型及最佳实践三个方面展开总结。
一、数据处理流程
前端监控数据的处理通常遵循采集、上报、清洗、聚合与分析的基本流程。
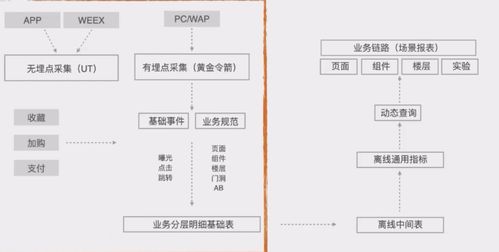
1. 数据采集:通过注入 SDK 或使用浏览器原生 API(如 Performance API、Error API)自动采集性能指标、错误日志、用户行为等数据。
2. 数据上报:采用 beacon API 或 img 标签等方式,确保数据在页面卸载前可靠发送至服务端。为减轻服务器压力,可实施抽样上报与合并上报策略。
3. 数据清洗:服务端对上报的原始数据进行校验、去重、格式化,剔除无效或恶意数据,提升数据质量。
4. 数据聚合与分析:利用流处理或批处理技术(如 Flink、Spark)对清洗后的数据进行实时或离线聚合,生成关键指标(如 p75、p95 响应时间)并支持多维分析。
二、存储方案选型
根据数据特性和查询需求,前端监控数据的存储需兼顾高性能、可扩展性与成本效益。
1. 时序数据库:如 InfluxDB、TimescaleDB,适用于存储和查询带时间戳的指标数据(如 FP、FCP、API 耗时),支持高效聚合与降采样。
2. 日志存储系统:如 Elasticsearch + Kibana,适合存储非结构化的错误日志与用户行为轨迹,提供强大的全文检索与可视化能力。
3. 对象存储:如 AWS S3、阿里云 OSS,用于归档原始日志和长期冷数据,降低成本。
4. 关系型数据库:如 MySQL、PostgreSQL,存储元数据、配置信息及聚合后的业务指标。
实践中常采用混合存储架构:时序数据库存指标,Elasticsearch 存日志,对象存储做备份,关系库管理元数据。
三、最佳实践
1. 数据分级:根据数据价值划分热、温、冷等级,实施差异化存储与保留策略,优化成本。
2. 数据治理:建立数据schema规范,确保字段一致性与语义明确;定期清理过期数据,避免存储膨胀。
3. 监控告警:在数据处理流水线中设置监控点,对数据延迟、丢失或异常进行实时告警。
4. 安全与合规:对敏感数据(如用户ID、IP)进行脱敏处理,遵守 GDPR 等数据隐私法规。
结语
前端监控的数据处理与存储服务是保障监控系统可靠性与可用性的基石。通过合理设计数据处理流水线、科学选型存储方案并践行最佳实践,团队能够构建出低延迟、高可用的前端监控体系,为业务优化与用户体验提升提供坚实的数据支撑。
如若转载,请注明出处:http://www.0meiyunhe.com/product/20.html
更新时间:2025-11-15 18:10:09