为什么MySQL选择B树作为索引结构 数据处理与存储的基石
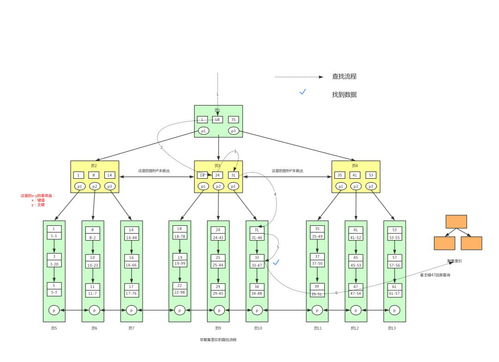
在数据库系统中,索引是提升查询效率的关键数据结构。MySQL的InnoDB和MyISAM等主流存储引擎广泛使用B树(及其变体B+树)作为索引的底层实现,这并非偶然,而是基于B树在数据处理与存储服务中的一系列核心优势。
1. 适应磁盘I/O特性:减少寻道时间
数据库数据通常存储在磁盘上,而磁盘访问(尤其是机械硬盘)的特点是顺序读取速度快,随机寻道(移动磁头)耗时高。B树是一种多路平衡搜索树,其每个节点可以包含多个键值和子节点指针(通常称为“阶”)。这种设计使得树的高度相对较低(例如,一个3层的B树就能存储数百万条记录),从而将大多数查询所需的磁盘I/O次数控制在很小的范围内(通常2-3次)。相比之下,二叉树(如AVL树、红黑树)虽然平衡,但每个节点只有两个分支,树的高度会随着数据量增长而快速增加,导致更多的磁盘访问,性能急剧下降。
2. 高效的范围查询与顺序访问
MySQL实际使用的是B+树,它是B树的一种优化变体。B+树的核心特点是:所有数据记录(或行数据)都存储在叶子节点中,且叶子节点之间通过指针连接成一个有序链表。内部节点(非叶子节点)仅存储键值(索引列的值)和指向子节点的指针,不存储实际数据。这种设计带来了两大好处:
- 范围查询高效:当执行
WHERE id BETWEEN 100 AND 200这类范围查询时,系统只需在B+树中找到起始键值所在的叶子节点,然后沿着链表顺序遍历即可,无需回溯到上层节点。
- 全表扫描更优:由于所有数据都在叶子节点链表中,顺序遍历整个表就像遍历链表一样高效,适合需要大量数据扫描的操作。
3. 稳定的查询性能:平衡与自调整
B树和B+树都是“平衡”树,意味着从根节点到任何叶子节点的路径长度基本相同。这保证了无论数据如何分布,查询、插入和删除操作的时间复杂度都是O(log n),其中n是数据量。数据库系统需要处理频繁的增删改查,B树在插入或删除数据时能通过节点分裂与合并自动维持平衡,避免了二叉树在极端情况下退化为链表(导致O(n)查询)的风险,从而提供了可预测的性能表现。
4. 充分利用存储块,减少I/O浪费
磁盘和操作系统通常以“页”(如4KB、16KB)为单位进行数据读写。B+树的节点大小被设计为与磁盘页大小对齐(例如InnoDB默认页大小为16KB)。一个节点可以存储大量键值(假设索引键是整型,一个页可能存上千个键),这使得一次磁盘I/O能加载更多有用信息到内存,极大地提升了数据局部性和缓存效率。相比之下,如果每个节点只存少量数据,会导致频繁的磁盘I/O,成为性能瓶颈。
5. 支持多种查询类型
基于B+树的索引天然支持最左前缀匹配,使得复合索引(多列索引)非常高效。例如,对(last<em>name, first</em>name)创建索引,查询WHERE last<em>name='Smith'或WHERE last</em>name='Smith' AND first_name='John'都能有效利用索引。B+树索引也适用于排序(ORDER BY)和分组(GROUP BY)操作,因为数据在叶子节点上已是有序状态。
对比其他数据结构
- 哈希索引:虽然哈希表提供O(1)的单点查询速度,但不支持范围查询和排序,且哈希冲突处理在磁盘上成本较高。MySQL的Memory引擎支持哈希索引,但InnoDB仅在自适应哈希索引中内部使用,主要索引仍是B+树。
- LSM树:在NoSQL数据库(如LevelDB、RocksDB)中流行,它优化了写入吞吐,但牺牲了读取一致性。MySQL的InnoDB引擎针对OLTP(在线事务处理)场景,需要强一致的读写性能,B+树仍是更合适的选择。
###
MySQL选择B树(尤其是B+树)作为索引结构的核心原因,在于它完美地平衡了磁盘I/O效率、查询性能稳定性以及对范围查询和事务处理的支持。其多路平衡、节点与磁盘页对齐、数据集中于叶子节点等特性,使得它成为关系型数据库在面向磁盘的存储系统中索引的理想解决方案。尽管新硬件(如SSD)和新型数据库(如使用LSM树的系统)带来了不同优化思路,但B+树在传统OLTP领域的地位依然稳固,是MySQL高效数据处理与存储服务的基石。
如若转载,请注明出处:http://www.0meiyunhe.com/product/71.html
更新时间:2026-02-01 15:06:19